

In deze use case willen we je meenemen in het verzamelen (scrapen) van data van een nieuwssite. Hiervoor zullen we gebruik maken van Python en je stap voor stap uitleggen wat er in de code gebeurt.
Gezien de huidige situatie leek ons het scrapen van data omtrent corona een actuele en zinvolle invulling van onze use case. Een grote rol in deze tijd speelt de GGD. Zij zijn onder andere betrokken bij de test- en vaccinatiestrategie. Twee onderwerpen die vaak voor veel discussies zorgen. Hoe zou de GGD de afgelopen maanden in het licht gezet zijn door de media? Zullen we verschillen zien in de loop van de tijd? Om aan deze data te komen zullen we van één nieuwswebsite (NOS) gebruik maken om de data te verzamelen. Daarnaast zullen we een sentimentanalyse uitvoeren om te onderzoeken hoe positief of negatief de artikelen geschreven zijn.
Stappenplan
We zullen je stap voor stap meenemen in het proces van scrapen. Als je op zoek bent naar een globale uitleg over wat scrapen is en als je iets meer wilt weten over hoe HTML-code in elkaar zit, dan kan je ons andere artikel checken waarin we conceptueel toelichten wat scrapen is. De onderstaande code vind je ook terug op GitHub.
Verzamelen artikel URL’s
Om aan de slag te kunnen moeten we als eerste een aantal packages inladen. Wij zullen BeautifulSoup als scraping package gebruiken, dat als redelijk intuïtief wordt gezien. Dus ook geschikt voor beginners! Requests zal BeautifulSoup aanvullen door het aanvragen van HTML-code mogelijk te maken. Verder hebben we nog wat standaard packages voor data wrangling nodig zoals pandas and itertools.

Na het inladen van de packages moeten we alle artikelen weten te vinden die te maken hebben met de GGD sinds het begin van corona. Hiervoor zijn we begonnen met simpelweg te zoeken op ‘GGD’ binnen de zoekfunctie van de NOS (https://nos.nl/zoeken?q=GGD). Het begin van corona hebben wij gedefinieerd als het begin van het publiceren van besmettingen vanuit het RIVM, waardoor we 1 januari 2020 als datumfilter hebben toegevoegd (https://nos.nl/zoeken?q=GGD&date=2020-01-01). Wat opvalt is dat lang niet alle artikelen verschijnen onder deze link. Hiervoor moet er doorgeklikt worden op ‘Meer resultaten tonen’ op het einde van de pagina. Om erachter te komen hoe we die kunnen integreren in de basis URL zoeken we in de HTML-code naar een specificatie:

Bij ‘data-url’ is te zien dat er een paginafilter in de link achter de ‘Meer resultaten tonen’-button hangt. Deze kunnen we gebruiken om door alle mogelijke pagina’s heen te loopen en de URL’s per pagina eraf te halen. We beginnen dus met onze basis URL: https://nos.nl/zoeken?q=GGD&date=2020-01-01&page=1. Daarnaast moeten we ook aangeven wanneer de laatste pagina is geweest zodat de loop na het laatste artikel stopt. Dit vertalen we naar een while-statement die na elke iteratie in de for-loop checkt of er nog wel een ‘Meer resultaten tonen’-button is.
Wat er in essentie in de code gebeurt is dat de basis URL benaderd wordt, de HTML-code gedownload wordt en hieruit alle artikellinks geëxtraheerd worden, terwijl er nog een ‘Meer resultaten tonen’-button is. Een belangrijke functie hierbij is soup.find() of soup.find_all(), die het extraheren uit de HTML-code op zich neemt. Hieraan worden de node en de class gevoerd van het gewenste onderdeel. In ons geval “a” en “search-results__link” voor de links van de artikelen en “span” en “js-update link-hover” voor de volgende pagina. In de comments in de code onderaan hebben we gespecificeerd wat er per onderdeel gebeurt.
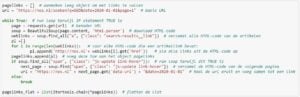
Verzamelen publicatiedatum
Naast de link van elk artikel willen we ook informatie over de publicatiedatum. Hiervoor voeren we dezelfde stappen uit als voor de links, maar passen we soup.find_all() dusdanig aan dat we de datum van het artikel krijgen.
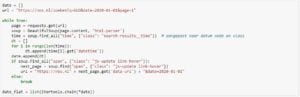
Verzamelen titel
Hetzelfde doen we ook nog een keer om de titel van elk artikel te vinden.
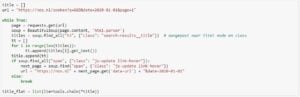
Verzamelen artikeltekst
Uiteindelijk willen we ook nog de tekst van elk artikel. Hiervoor moeten we niet bij de basis URL’s zijn, maar moeten we de informatie uit de links van de artikelen halen (de hierboven aangemaakte ‘pagelinks’). De buitenste for loop itereert over alle links van de artikelen heen (‘list_links’) en haalt de tekst uit de desbetreffende link. Hierbij maken we verschil tussen artikelen die een video bevatten en gewone artikelen omdat de class voor deze twee varianten verschilt. In de tweede for loop slaan we de informatie op.

Nadat voor elk artikel de datum, titel en tekst verzameld is, plaatsen we deze gegevens in een dataframe. Dit dataframe ziet er als volgt uit:

Nu we de datum, titel en tekst hebben verzameld is het scrapegedeelte afgerond en kunnen de bewerkingen en analyses gedaan worden. Wij hebben ervoor gekozen om een sentimentanalyse te doen en de resultaten te visualiseren. De code die we voor deze analyse en voor het maken van de plots gebruikt hebben, is te vinden op GitHub.
In de eerste figuur zien we het verschil tussen de positieve en negatieve sentimenten van de artikelen, opgesplitst in artikelen die over vaccinaties en over andere onderwerpen gaan. Er is in deze figuur een positieve piek van vaccinatieartikelen te zien aan het einde van 2020, wat hoogstwaarschijnlijk samenhangt met het nieuws dat er vaccinaties beschikbaar kwamen en er snel gestart kon worden.
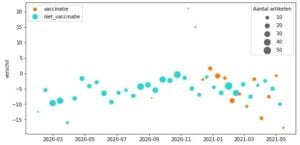
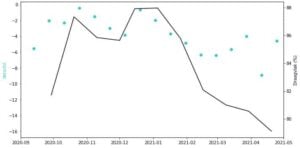
Voor de tweede plot hebben we gebruik gemaakt van openbare data over gedrag van het RIVM. We zien dat het draagvlak van de bevolking de lijn van het sentiment lichtjes volgt. Het omslagpunt rond de start van de vaccinatie lijkt het draagvlak ook positief beïnvloed te hebben.
Je hebt het einde van de Use Case gehaald! Hopelijk hebben we jou kunnen laten zien wat voor krachtige tool scrapen is in de huidige wereld en hebben we een voorbeeld gegeven dat laat zien hoe nuttig scrapen kan zijn. Met de data die we hebben zijn er nog oneindig veel mogelijkheden om nog verder mee te experimenteren en analyses op los te laten. Maak daar vooral gebruik van en ga lekker zelf aan de slag!
Deze Use Case is geschreven en ontwikkeld door Nele Wensauer & Sanne Beurskens.


