

Het verkrijgen en behouden van goede data is van groot belang wanneer je er zinvolle en bruikbare resultaten uit wilt halen. Of de data nu wordt verzameld, opgeslagen of verwerkt, bij elke stap is er een kans dat de originele waarde of de betekenis ervan (in relatie tot andere waardes), verdwijnt of verandert (1). Om de kwaliteit van de data te waarborgen kunnen veel verschillende methoden worden toegepast, zowel tijdens als na het verzamelen. Hier volgen een paar van de meest voorkomende problemen met data en een aantal trucs om deze aan te pakken.
Data Profiling – klopt de data?
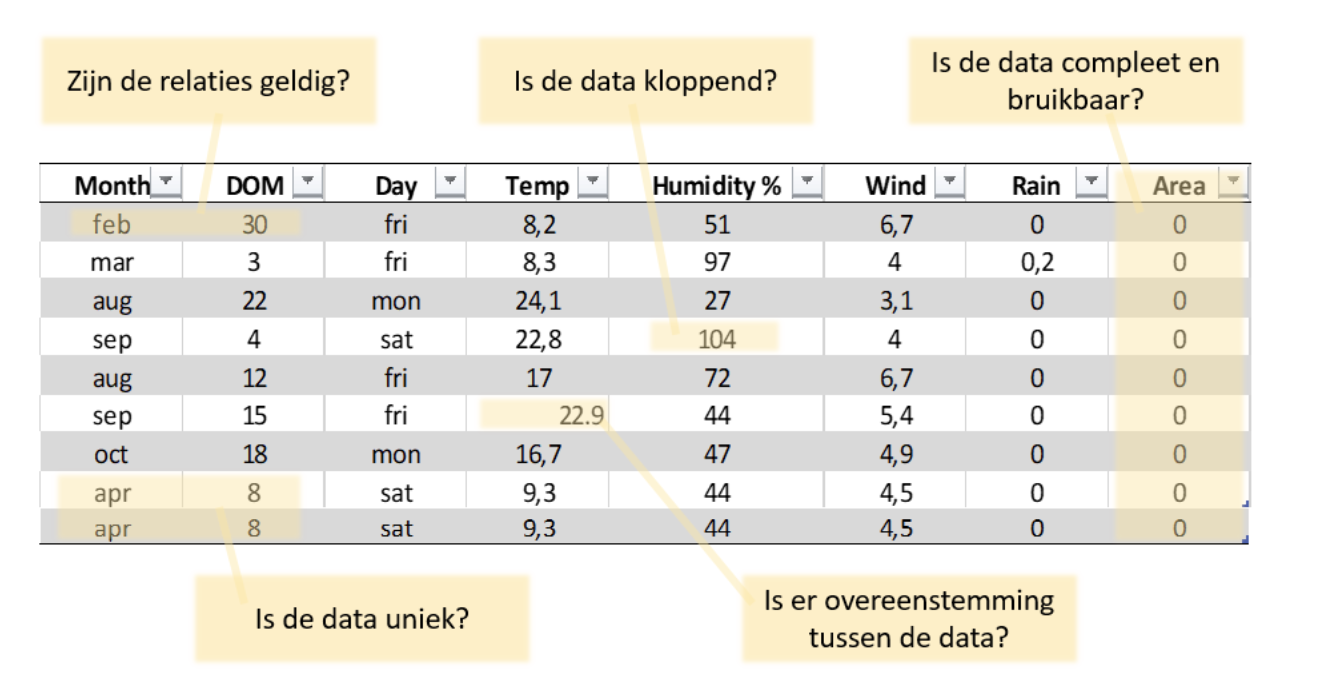
Het liefst willen we natuurlijk een mooi script gebruiken om automatisch eventuele problemen met de data op te sporen, toch kun je het beste beginnen met het ‘handmatig’ doornemen van je data. Let hierbij voornamelijk op of de data kloppend is, en of je de waardes redelijkerwijs zou mogen verwachten. Dit wordt ook wel data profiling genoemd (2). Bekijk in eerste instantie de bovenste en onderste 10-20 rijen en doe dit voor elke kolom/variabele gesorteerd. Ook is het zeker verstandig om een samenvatting van je data te bekijken, in R doe je dit bijvoorbeeld met de summary() functie. Met wat voor data je ook werkt, je zult waarschijnlijk snel kunnen zien of er afwijkende waardes in de data zitten. Temperaturen die buiten een normaal bereik vallen, waardes die een factor 1000 kleiner of groter zijn dan verwacht, of tekst in plaats van numerieke waardes zullen meteen opvallen. Hier geldt natuurlijk wel: Hoe meer je over de data weet, hoe makkelijker het is om de data te controleren.
Het is nu belangrijk om te bepalen wat je met dit soort data doet, je hebt vier opties:
- Accepteren. Je laat de waarde zoals die is. Wanneer je bijvoorbeeld te maken hebt met typfouten of andere slordigheden, maar je zeker weet dat het geen effect heeft op verdere analyse, kun je dit overwegen.
- Afwijzen. De hele entry verwijderen als de juiste informatie niet te achterhalen is. Dit is een veilige optie, maar kan ervoor zorgen dat bepaalde analyses minder kracht hebben en het moeilijker wordt om conclusies te trekken.
- Corrigeren. Bij kleine datasets kun je handmatig de fouten verbeteren, bij grotere datasets is het soms mogelijk om de hele kolom aan te passen (denk bijvoorbeeld aan het verwisselen van een ‘.’ en ‘,’ waardoor alle waardes een factor 1000 afwijken). Let hierbij goed op dat je weet wat de fout heeft veroorzaakt en je de daadwerkelijke waarde weet of kunt achterhalen!
- Invullen als onbekend/NA. Wanneer het niet wenselijk/mogelijk is de hele entry te verwijderen maar de data duidelijk niet klopt. In feite maak je er nu missende data van, wat ook weer gevolgen heeft voor het verdere proces.
Missende data
Nu we de data kloppend hebben gemaakt kunnen we de missende data aanpakken. Het missen van data is een veelbesproken onderwerp in de datawetenschappen (3), er is zelfs een aparte cursus op DataCamp over hoe hiermee om te gaan (voor zowel R als Python) (4 & 5). Het is vaak belangrijk om te achterhalen waarom er iets mist in je database, zodat je ervoor kunt zorgen dat het probleem zich in de toekomst niet meer voordoet. Het kan zijn dat het nooit is verzameld, maar het kan ook zijn verloren tijdens het verwerken of verplaatsen van de data. Ook waardes die zo zijn aangepast dat ze effectief onbruikbaar zijn geworden, kunnen als missend worden bestempeld. Missende data kan zich op verschillende manieren voordoen, afhankelijk van de methoden en software die je gebruikt, maar let op waardes als NA (Not Available) en NaN (Not a Number). Heb je te maken met dit soort data? Dan heb je vaak meerdere opties, waaronder het verwijderen van de entry of het invullen van de waarde op basis van andere data (in dezelfde kolom). Je kunt er ook voor kiezen om een functie te schrijven die missende data vervangt door het gemiddelde van de kolom, of met andere statistische waardes. Dit proces wordt ook wel imputation genoemd (6). Een andere indicatie dat er iets mis kan zijn met jouw data zijn de NULL en Inf waardes, echter betekenen deze niet dat er iets mist, enkel dat de waarde niet is ingevuld (bijvoorbeeld in een online vragenlijst) of respectievelijk oneindig is (bijvoorbeeld door een onjuiste berekening). Ook deze entries zullen in de meeste gevallen een onvoorspelbaar effect hebben op je analyse en dus is het belangrijk om ze mee te nemen in de kwaliteitscontrole.
Andere kwaliteitsproblemen
Andere veel voorkomende problemen in databases zijn problemen met conversie en formaten van de data. Met andere woorden; is er overeenstemming tussen verschillende data? Denk aan het datumformaat, die bij ons als dag/maand/jaar wordt geschreven maar in andere delen van de wereld als maand/dag/jaar. Ook de conversie (of het gebrek ervan) tussen waardes die temperaturen of valuta beschrijven kunnen fout gaan, let dus extra op bij dit soort datasets. Duplicaten van entries komen helaas ook voor in bepaalde datasets en zijn vaak het gevolg van gebrekkige dataverwerking. Je kunt deze data opsporen door in R de functie duplicated() te gebruiken en besluiten overbodige, niet unieke, entries verwijderen. Daarnaast kun je de data onderwerpen aan een controle op geldigheid. Dit betekent bijvoorbeeld dat voor elke naam maar één e-mailadres mogelijk zou mogen zijn. En vind je een BSN gekoppeld aan twee verschillende personen, dan moet je in de meeste gevallen concluderen dat er toch echt een fout in jouw data zit. Het begrijpen van de relaties van verschillende waardes en de betekenis van jouw data is hier belangrijk.
Niet alle data hoeft perfect te zijn. De kwaliteit van data wordt uiteindelijk in grote mate bepaald door de gebruiker zelf en is onder andere afhankelijk van de vragen die ermee moeten worden beantwoord. Missende data in één kolom heeft bijvoorbeeld lang niet altijd effect op analyses die worden uitgevoerd op andere kolommen. Let bij jouw kwaliteitscontrole dus voornamelijk op de punten zoals hieronder weergegeven. Als je deze vijf vragen hebt beantwoord, kun je met een gerust hart door met de volgende stap. Let erop dat je de data misschien nog wilt opschonen voordat je begint met analyseren. Succes!
Referenties:
- Singh & Singh. 2010. A Descriptive Classification of Causes of Data Quality Problems in Data Warehousing. IJCSI International Journal of Computer Science Issues, Vol. 7, Issue 3, No 2, May 2010. https://pdfs.semanticscholar.org/a0b3/03955e1d05f8338b426111392ee749ac1a60.pdf
- https://neilpatel.com/blog/data-quality/
- https://www.kdnuggets.com/2020/06/missing-values-dataset.html
- https://learn.datacamp.com/courses/dealing-with-missing-data-in-r
- https://learn.datacamp.com/courses/dealing-with-missing-data-in-python
- https://medium.com/acing-ai/ml-ops-data-science-version-control-5935c49d1b76