

Momenteel wordt een grote hoeveelheid data gedeeld over COVID-19, het coronavirus. Het RIVM verspreidt bijvoorbeeld dagelijks de stand van zaken van het aantal besmettingen. Naast deze data verschijnen er gegevens waar je soms je vraagtekens bij moet zetten: van ongegronde vergelijkingen tot verkeerd geïnterpreteerde grafieken. In deze tijd van crisis is het (extra) belangrijk om onderscheid te maken tussen feit en fictie. In deze blog leggen wij met behulp van populaire corona-data de basisprincipes van het weergeven en interpreteren van data ten tijde van een epidemie uit.
De afgelopen maand ging een lijstje met het aantal besmettingen in Nederland en Italië rond op sociale media. De boodschap: het verloop van het aantal besmettingen in Nederland vanaf 16 maart lijkt sterk op het aantal in Italië twee weken eerder. Nederland is er dus slecht aan toe. Deze tabel is echter misleidend, er wordt bijvoorbeeld gebruik gemaakt van een willekeurig beginpunt: rond de 30 doden. Wanneer beide landen worden vergeleken vanaf de dag dat er voor het eerst iemand aan corona overleed, ziet het plaatje er voor Nederland gunstiger uit. Ook zien we nu, een weken later, dat het verloop in Nederland er (gelukkig) heel anders uitziet dan in Italië.
Vergelijking tussen landen
We willen natuurlijk graag weten of de maatregelen die we in Nederland nemen werken, en of wij het goed doen in vergelijking met andere landen. Echter, de vergelijking van het aantal besmettingen tussen landen is moeilijk te maken, doordat belangrijke informatie niet wordt meegenomen, er verschillen tussen landen zijn en de effecten van maatregelen op zo’n korte termijn nog niet duidelijk te meten zijn. Hierdoor is het nog moeilijk te zeggen of Nederland het goed doet in de strijd tegen corona.
Allereerst de missende informatie: slechts een deel van de besmette mensen wordt getest, waardoor de huidige besmettingscijfers onvolledig zijn. Dit komt voornamelijk door een gebrek aan testcapaciteit in Nederland waardoor niet alle personen met symptomen kunnen worden getest en dus een groot deel van de geïnfecteerde personen wordt gemist. Om hiervoor te corrigeren, weten we echter niet of we het aantal geïnfecteerde personen in Nederland moeten vermenigvuldigen met een factor 2 of een factor 200. Door deze onvolledige cijfers, waar andere landen ook mee te kampen hebben, is het moeilijk een vergelijking te maken tussen landen.
Naast dat veel landen te kort hebben aan tests, zoals in Nederland waar alleen mensen met een hoog risico worden getest, zijn er in andere landen zogenaamde corona drive-by centra, die alle mensen test die ziekteverschijnselen hebben. In Zuid-Korea neemt men zelfs bij een groot deel van de bevolking de test af. Op deze manier krijg je in andere landen vanzelfsprekend hogere besmettingsaantallen.
Ook de bevolkingssamenstelling tussen landen verschilt. COVID-19 manifesteert zich verschillend per geslacht en leeftijdsgroep. Mensen die binnen de risicogroep vallen, bijvoorbeeld ouderen, zullen vaak meer last hebben van de gevolgen van corona, dan de rest van de bevolking. Dit zorgt ervoor dat in landen waarbij een hoger percentage binnen de risico-groep valt, meer mensen in het ziekenhuis belanden. Dit heeft vervolgens weer invloed op de gerapporteerde besmettingscijfers.
Voorspellingen
Om deze redenen is het dan ook onmogelijk om, gebaseerd op Italiaanse cijfers, te voorspellen hoeveel mensen er de komende tijd besmet gaan worden in Nederland. Elke week zijn er nieuwe maatregelen om het aantal besmettingen te verkleinen. Omdat het 2 weken kan duren voordat iemand die besmet is ziek wordt, duurt het minstens zo lang voordat je het effect van maatregelen terug gaat zien. Het is een nieuw virus waarvan nog niemand weet hoe het zich precies gaat gedragen. De komende tijd zal er meer en meer data beschikbaar komen over het virus zelf, de effecten van bepaalde maatregelen en mogelijke oplossingen.
Ondanks deze onzekerheden wordt er wel degelijk geprobeerd om het aantal besmettingen te voorspellen, door middel van statistische modellen en groeicurven. Eindhovense datawetenschappers zijn momenteel bezig met het maken van modellen die het aantal nieuwe besmettingen op korte termijn proberen te voorspellen. Voor de landen die het zwaarst getroffen zijn kunnen de onderzoekers al met een nauwkeurigheid van 81 procent drie dagen vooruit voorspellen, dus door het toepassen van de modellen zitten ze met hun voorspellingen gemiddeld genomen 19% af van het daadwerkelijke aantal besmettingen.
Juiste weergave data tijdens een epidemie
Bij de gewone griep verzamelt het Nederlands Instituut voor Onderzoek van de Gezondheidszorg (NIVEL) informatie over de besmettingen in Nederland en onderzoekt of er sprake is van een epidemie. Zij ontvangt vanuit veertig huisartsenpraktijken in Nederland wekelijks een lijstje met het aantal mensen dat met griepverschijnselen de dokter bezoekt. Deze huisartsenpraktijken zijn verspreid over het land en verlenen zorg aan ongeveer 1% van de Nederlandse bevolking. Op deze manier wordt de bepaling gedaan onder een representatieve steekproef van onze bevolking en deze gegevens worden gebruikt om te bepalen of er een epidemie is. Momenteel nemen de aangesloten huisartspraktijken monsters af van patiënten met luchtweginfecties om te testen op het coronavirus, echter bezoeken niet alle geïnfecteerde patiënten de huisarts. Geen enkel land heeft representatieve data over besmettingen onder een willekeurige steekproef van de bevolking, laat staan van een steekproef die de samenstelling van de bevolking accuraat weergeeft.
Ook is het aan te raden om niet te proberen om de besmettingsgraad en de sterftekans uit te drukken als losstaand getal. Door de mate van onzekerheid in het werkelijke aantal besmettingen is het beter om deze aantallen weer te geven door middel van een range. Ook moet er meer nadruk liggen op het onzekere karakter van de data, bijvoorbeeld door toe te voegen dat de getallen bij benadering zijn.
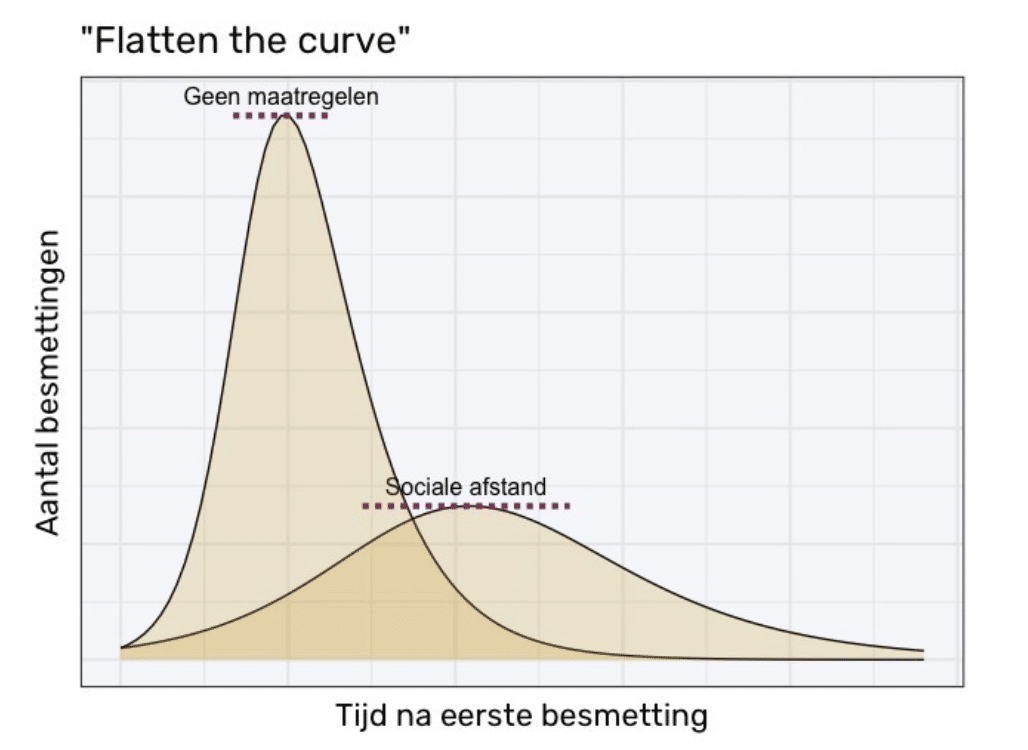
Flatten the curve
Zou de onvolledigheid van de getallen de reden zijn dat in de bekende grafiek over “Flattening the curve” de aantallen op de assen ontbreken? Of wil niemand zich wagen aan een schatting van het aantal mensen dat besmet gaat raken? Deze bekende grafiek legt het principe uit van het effect van sociale onthouding op de bezetting van het medische systeem, maar de weergave in de grafiek zelf is weinig zeggend: de lezer heeft geen idee hoeveel besmettingen ons medisch systeem aan kan en in hoeveel dagen de epidemie ons medisch systeem overgroeit. Ook al ziet deze grafiek er dus uit als een precieze weergave van bestaande data, hij is alleen bedoeld om een concept uit te leggen. Het doel van deze grafiek is namelijk om weer te geven dat door de infectie geleidelijk over een langere periode door de populatie te laten gaan, 40 tot 70% van de populatie wordt besmet en het medisch systeem niet overbelast raakt. Hoelang deze periode moet duren wordt niet duidelijk uit deze figuur: gaat het om dagen, maanden, of misschien zelfs jaren?
De komende periode zullen er naast grappige filmpjes en ongegronde gezondheidstips vast meer data en figuren ‘Viral’ gaan. Hierbij is het belangrijk te kijken naar de bron waar de data vandaan komt en dus kritisch te zijn richting de conclusies die getrokken worden. De komende tijd willen we jullie op de hoogte houden houden van de waarde van data en figuren die online opduiken. Wil je meer weten over dit onderwerp, laat het dan weten: wij staan klaar om je te helpen!
Gemaakt door Margreet Vonk Noordegraaf en Jolien Jansen werkzaam bij trainee.nl detachering bureau gespecialiseerd in business analytics & data science.
Bronnen
https://www.icthealth.nl/nieuws/wetenschappers-berekenen-groei-coronavirus-uitbraak/
https://www.nivel.nl/nl/uitgelicht/monitoring-de-covid-19-uitbraak
https://www.worldometers.info/coronavirus/
Meer info:
https://www.casperalbers.nl/nl/post/2020-03-11-coronagrafieken/